





Reddit is suing Anthropic for allegedly using the site’s data to train AI models without a proper licensing agreement, according to a complaint filed in a Northern California court on Wednesday. Reddit claims in the complaint that Anthropic’s unauthorized use of the site’s data for commercial purposes was unlawful, and alleges the AI startup violated Reddit’s user agreement.
Reddit’s lawsuit makes it the first Big Tech company to legally challenge an AI model provider over its training data practices, joining a litany of publishers that have sued tech companies on similar grounds.
The New York Times has sued OpenAI and Microsoft for training on its news articles without payment or permission. Meanwhile, Sarah Silverman and other book authors have sued Meta for training AI models on their books without approval. Music publishers and artists have also brought similar claims against AI audio, video, and image generation startups, alleging misuse of their content.
“We will not tolerate profit-seeking entities like Anthropic commercially exploiting Reddit content for billions of dollars without any return for redditors or respect for their privacy,” said Ben Lee, Reddit’s chief legal officer, in a statement to TechCrunch.
Notably, Reddit has inked deals with other AI model providers, including OpenAI and Google, that allow these companies to train AI models on Reddit’s data and have the site’s posts appear in their respective AI chatbots’ answers. However, in the filing, Reddit says it subjects OpenAI and Google to certain terms that protect its users’ interests and privacy.
Sam Altman, the CEO of OpenAI, has an 8.7% stake in Reddit, making him the third-largest shareholder, and was once a member of the company’s board of directors.
In the filing, Reddit claims that it approached Anthropic and made clear that the AI startup did not have authorization to scrape or use Reddit’s content. However, Reddit alleges that Anthropic “refused to engage.”
Anthropic did not immediately provide a comment when reached by TechCrunch.
Reddit claims in its complaint that Anthropic’s scraper bots ignored the social network’s robots.txt files, a standard that signals to automated systems not to crawl websites. As further evidence that Anthropic trained on Reddit data, Reddit alleges that Anthropic’s AI chatbot, Claude, frequently references Reddit communities and topics on Reddit.
Reddit is asking Anthropic to pay compensatory damages, as well as restitution for the amount by which Anthropic has been enriched by scraping Reddit’s content. Reddit also requests an injunction prohibiting Anthropic from continuing to use Reddit’s content.

Suspect arrested after threats against TikTok’s Culver City headquarters
Police say they have arrested a suspect allegedly connected to multiple online threats that led TikTok to evacuate its headquarters...

Department of Energy cancels $7.5B of clean energy projects in mostly blue states
The Department of Energy said Wednesday night it was canceling 321 awards worth $7.56 billion that were largely focused on...
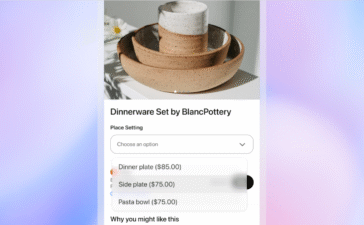
OpenAI takes on Google, Amazon with new agentic shopping system
ChatGPT users in the U.S. can now make Etsy and Shopify purchases within conversations, marking a next step towards the future of online...

Discover how developer tools are shifting fast at Disrupt 2025
The idea of hiring your “first critical engineer” is getting a serious reality check at TechCrunch Disrupt 2025, October 27–29...